# Java 编码规范
根植于教育,服务于师生
# SonarQube
- 项目已配置SonarQube静态代码扫描,Java语言采用阿里的P3C规范。项目经理根据需要在项目过程中安排团队进行代码评审,并输出《代码评审报告》。要求SonarQube代码质量报告中禁止出现BUG类型和漏洞类型,单个Maven子项目的技术债务不得超过8小时。
- SonarQube报告地址:http://192.168.0.200:9000/sonar/projects
# P3C插件
- 在IDEA中集成P3C插件,在编码过程中实时对代码规范进行检验,出现错误提示后及时进行修正。
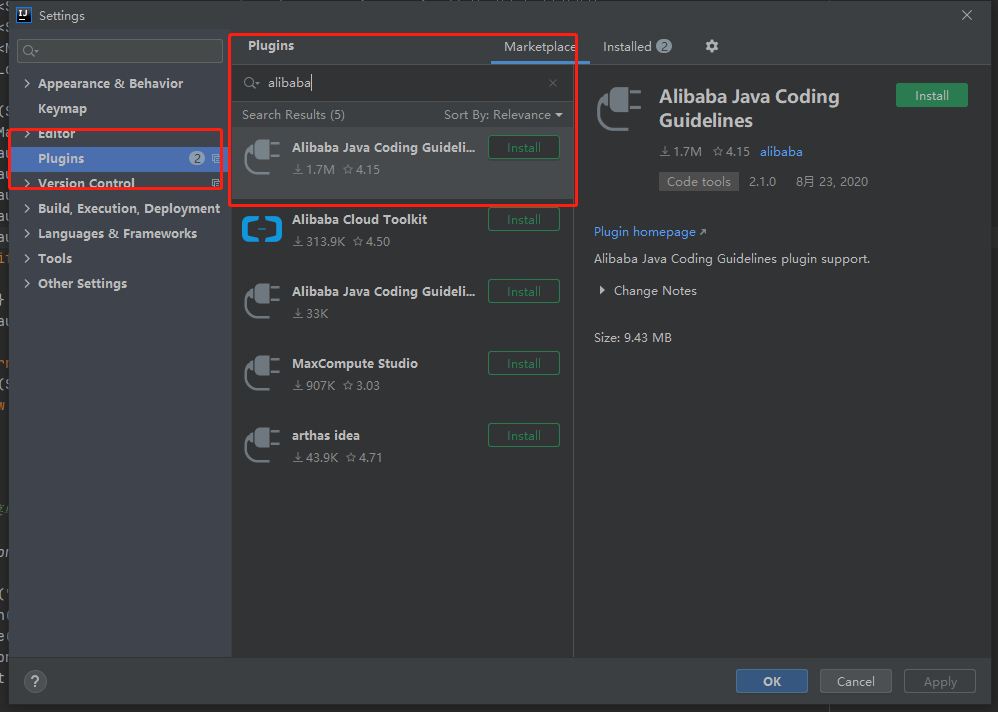
- IDEA中P3C安装方法:
File→Setting 打开系统设置,检索关键字 alibaba 即可
- P3C插件使用方法:
鼠标右键开启实时检测:

在出现提示错误后,进行修改:
# 编程规约
# 命名风格
- 1.代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
反例:_name / __name / $name / name_ / name$ / name__
- 2.所有编程相关的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。
注意:纯拼音命名方式更要避免采用。
正例:ali / alibaba / taobao / cainiao/ aliyun/ youku / hangzhou 等国际通用的名称,可视同英文。
反例:DaZhePromotion [打折] / getPingfenByName() [评分] / String fw[福娃] / int 某变量 = 3
- 3.类名使用
UpperCamelCase风格,但以下情形例外:DO / BO / DTO / VO / AO /PO / UID等。
正例:ForceCode / UserDO / HtmlDTO / XmlService / TcpUdpDeal / TaPromotion
反例:forcecode / UserDo / HTMLDto / XMLService / TCPUDPDeal / TAPromotion
- 4.方法名、参数名、成员变量、局部变量都统一使用
lowerCamelCase风格。
正例: localValue / getHttpMessage() / inputUserId
- 5.常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例:MAX_STOCK_COUNT / CACHE_EXPIRED_TIME
反例:MAX_COUNT / EXPIRED_TIME
6.抽象类命名使用
Abstract或Base开头;异常类命名使用Exception结尾;测试类 命名以它要测试的类的名称开始,以Test结尾。7.类型与中括号紧挨相连来表示数组。
正例:定义整形数组 int[] arrayDemo。
反例:在 main 参数中,使用 String args[] 来定义。
- 8.POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
说明:在本文 MySQL 规约中的建表约定第一条,表达是与否的变量采用
is_xxx的命名方式,所以,需要在<resultMap>设置从is_xxx到xxx的映射关系。
反例:定义为基本数据类型 Boolean isDeleted 的属性,它的方法也是 isDeleted(),框架在反向解析的时候,“误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。
- 9.包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
正例:应用工具类包名为 com.alibaba.ei.kunlun.aap.util、类名为 MessageUtils(此规则参考 spring 的框架结构)
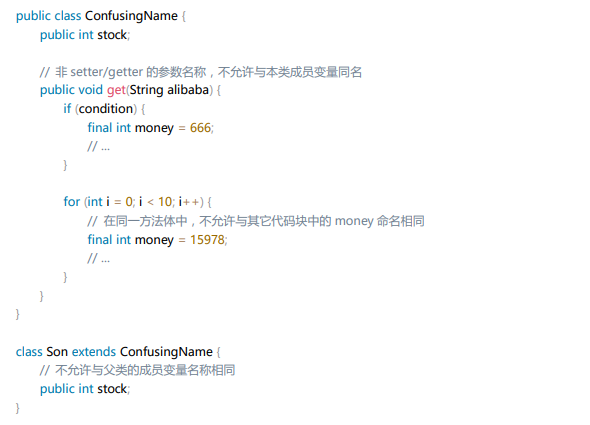
- 10.避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名,使可理解性降低。
说明:子类、父类成员变量名相同,即使是
public类型的变量也能够通过编译,另外,局部变量在同一方法内的不同代码块中同名也是合法的,这些情况都要避免。对于非setter/getter的参数名称也要避免与成员变量名称相同。
反例:
- 11.杜绝完全不规范的缩写,避免望文不知义。
反例:AbstractClass“缩写”成 AbsClass;condition“缩写”成 condi;Function 缩写”成 Fu,此类 随意缩写严重降低了代码的可阅读性
- 12.为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词组 合来表达。
正例:对某个对象引用的 volatile 字段进行原子更新的类名为 AtomicReferenceFieldUpdater。
反例:常见的方法内变量为 int a;的定义方式。
- 13.在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。
正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT
反例:startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD
- 14.如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。
正例:
public class OrderFactory;
public class LoginProxy;
public class ResourceObserver;
2
3
15.接口和实现类的命名有两套规则。
15.1 对于
Service和DAO类,基于 SOA 的理念,暴露出来的服务一定是接口,内部的实现类用Impl的后缀与接口区别。正例:
CacheServiceImpl实现CacheService接口。15.2 如果是形容能力的接口名称,取对应的形容词为接口名(通常是–able 的形容词)。
正例:
AbstractTranslator实现Translatable接口。
16.各层命名规约。
- A)Service/DAO 层方法命名规约
1)获取单个对象的方法用
get做前缀。
2)获取多个对象的方法用list做前缀,复数结尾,如:listObjects。
3)获取统计值的方法用count做前缀。
4)插入的方法用save/insert做前缀。
5)删除的方法用remove/delete做前缀。
6)修改的方法用update做前缀。- B)领域模型命名规约
1)数据对象:
xxxDO,xxx即为数据表名
2)数据传输对象:xxxDTO,xxx为业务领域相关的名称。
3)展示对象:xxxVO,xxx一般为网页名称。
4)POJO是DO/DTO/BO/VO的统称,禁止命名成xxxPOJO。- A)Service/DAO 层方法命名规约
# 常量定义
1.不允许任何魔法值(即未经预先定义的常量)直接出现在代码中。
2.在 long 或者 Long 赋值时,数值后使用大写字母 L,不能是小写字母 l,小写容易跟数字混淆,造成误解。
说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?
- 3.不要使用一个常量类维护所有常量,要按常量功能进行归类,分开维护。
说明:大而全的常量类,杂乱无章,使用查找功能才能定位到修改的常量,不利于理解,也不利于维护。
正例:缓存相关常量放在类 CacheConsts 下;系统配置相关常量放在类 SystemConfigConsts 下。
- 4.如果变量值仅在一个固定范围内变化用 enum 类型来定义。
# 代码格式
1.如果是大括号内为空,则简洁地写成{}即可,大括号中间无需换行和空格;如果是非空代码块则:
- 1)左大括号前不换行。
- 2)左大括号后换行。
- 3)右大括号前换行。
- 4)右大括号后还有 else 等代码则不换行;表示终止的右大括号后必须换行。
2.左小括号和右边相邻字符之间不出现空格;右小括号和左边相邻字符之间也不出现空格;而左大括号前需要加空格。详见第 5 条下方正例提示。
反例:if (空格 a == b 空格)
3.
if/for/while/switch/do等保留字与括号之间都必须加空格。4.任何二目、三目运算符的左右两边都需要加一个空格。
说明:包括赋值运算符=、逻辑运算符&&、加减乘除符号等。
- 5.采用 4 个空格缩进,禁止使用 Tab 字符。
说明:如果使用 Tab 缩进,必须设置 1 个 Tab 为 4 个空格。IDEA 设置 Tab 为 4 个空格时,请勿勾选
Use tab character;而在Eclipse中,必须勾选insert spaces for tabs。
正例: (涉及 1-5 点)

- 6.注释的双斜线与注释内容之间有且仅有一个空格。
正例:
// 这是示例注释,请注意在双斜线之后有一个空格
String commentString = new String();
2
- 7.在进行类型强制转换时,右括号与强制转换值之间不需要任何空格隔开。
正例:
double first = 3.2d;
int second = (int)first + 2;
2
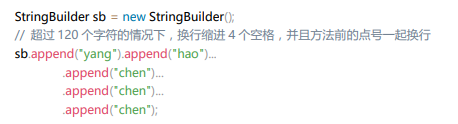
8.单行字符数限制不超过 120 个,超出需要换行,换行时遵循如下原则:
- 1)第二行相对第一行缩进 4 个空格,从第三行开始,不再继续缩进,参考示例。
- 2)运算符与下文一起换行。
- 3)方法调用的点符号与下文一起换行。
- 4)方法调用中的多个参数需要换行时,在逗号后进行。
- 5)在括号前不要换行,见反例。
正例:
反例:

- 9.方法参数在定义和传入时,多个参数逗号后面必须加空格。
正例:
// 下例中实参的 arg1 ,后边必须要又一个空格
method(args1, args2, args3)
2
10.IDE 的
text file encoding设置为UTF-8; IDE 中文件的换行符使用Unix格式,不要 使用Windows格式。11.单个方法的总行数不超过 80 行。
说明:除注释之外的方法签名、左右大括号、方法内代码、空行、回车及任何不可见字符的总行数不超过 80 行。
正例:代码逻辑分清红花和绿叶,个性和共性,绿叶逻辑单独出来成为额外方法,使主干代码更加清晰;共性逻辑抽取成为共性方法,便于复用和维护。
- 12.没有必要增加若干空格来使变量的赋值等号与上一行对应位置的等号对齐。
正例:
int one = 1;
long two = 2L;
float three = 3F;
StringBuilder sb = new StringBuilder();
2
3
4
说明:增加 sb 这个变量,如果需要对齐,则给 one、two、three 都要增加几个空格,在变量比较多的情况下,是非常累赘的事情。
# OOP 规约
1.避免通过一个类的对象引用访问此类的静态变量或静态方法,无谓增加编译器解析成本,直接用类名来访问即可。
2.所有的覆写方法,必须加
@Override注解。
说明:
getObject()与get0bject()的问题。一个是字母的 O,一个是数字的 0,加@Override可以准确判断是否覆盖成功。另外,如果在抽象类中对方法签名进行修改,其实现类会马上编译报错。
- 3.相同参数类型,相同业务含义,才可以使用 Java 的可变参数,避免使用
Object。
说明:可变参数必须放置在参数列表的最后。(建议开发者尽量不用可变参数编程)
正例:public List listUsers(String type, Long... ids) {...}
4.外部正在调用或者二方库依赖的接口,不允许修改方法签名,避免对接口调用方产生影响。接口过时必须加
@Deprecated注解,并清晰地说明采用的新接口或者新服务是什么。5.不能使用过时的类或方法。
说明:
java.net.URLDecoder中的方法decode(String encodeStr)这个方法已经过时,应该使用双参数decode(String source, String encode)。接口提供方既然明确是过时接口,那么有义务同时提供新的接口; 作为调用方来说,有义务去考证过时方法的新实现是什么。
- 6.
Object的equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals
正例:"test".equals(object);
反例:object.equals("test");
说明:推荐使用 JDK7 引入的工具类 java.util.Objects#equals(Object a, Object b)
- 7.所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于
Integer var = ?在-128至127之间的赋值,Integer对象是在IntegerCache.cache产生, 会复用已有对象,这个区间内的Integer值可以直接使用==进行判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用equals方法进行判断。
8.任何货币金额,均以最小货币单位且整型类型来进行存储。
9.浮点数之间的等值判断,基本数据类型不能用
==来比较,包装数据类型不能用equals来判断。
说明:浮点数采用“尾数+阶码”的编码方式,类似于科学计数法的“有效数字+指数”的表示方式。二进制无法精确表示大部分的十进制小数。
反例:

正例:

- 10.如上所示
BigDecimal的等值比较应使用compareTo()方法,而不是equals()方法。
说明:
equals()方法会比较值和精度(1.0 与 1.00 返回结果为false),而compareTo()则会忽略精度。
- 11.定义数据对象
DO类时,属性类型要与数据库字段类型相匹配。
正例:数据库字段的 bigint 必须与类属性的 Long 类型相对应。
反例:某个案例的数据库表 id 字段定义类型 bigint unsigned,实际类对象属性为 Integer,随着 id 越来 越大,超过 Integer 的表示范围而溢出成为负数。
- 12.禁止使用构造方法
BigDecimal(double)的方式把double值转化为BigDecimal对象。
说明:
BigDecimal(double)存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常。 如:BigDecimal g = new BigDecimal(0.1F);实际的存储值为:0.10000000149
正例:优先推荐入参为 String 的构造方法,或使用 BigDecimal 的 valueOf 方法,此方法内部其实执行了 Double 的 toString,而 Double 的 toString 按 double 的实际能表达的精度对尾数进行了截断。

13.关于基本数据类型与包装数据类型的使用标准如下。
- 1)所有的
POJO类属性必须使用包装数据类型。 - 2)
RPC方法的返回值和参数必须使用包装数据类型。 - 3)所有的局部变量使用基本数据类型。
- 1)所有的
说明:
POJO类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何 NPE 问题,或者入库检查,都由使用者来保证。
正例:数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险。
反例:某业务的交易报表上显示成交总额涨跌情况,即正负 x%,x 为基本数据类型,调用的 RPC 服务,调 用不成功时,返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线-。所以包装数据类型 的 null 值,能够表示额外的信息,如:远程调用失败,异常退出。
- 14.定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
反例:POJO 类的 createTime 默认值为 new Date(),但是这个属性在数据提取时并没有置入具体值,在 更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间。
- 15.序列化类新增属性时,请不要修改
serialVersionUID字段,避免反序列失败;如果 完全不兼容升级,避免反序列化混乱,那么请修改serialVersionUID值。
说明:注意
serialVersionUID不一致会抛出序列化运行时异常。
16.构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在
init方法中。17.POJO 类必须写
toString方法。使用 IDE 中的工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下super.toString。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
- 18.禁止在 POJO 类中,同时存在对应属性 xxx 的 isXxx()和 getXxx()方法。
框架在调用属性 xxx 的提取方法时,并不能确定哪个方法一定是被优先调用到的。
- 19.使用索引访问用
String的split方法得到的数组时,需做最后一个分隔符后有无内容 的检查,否则会有抛IndexOutOfBoundsException的风险。
说明:

20.当一个类有多个构造方法,或者多个同名方法,这些方法应该按顺序放置在一起,便 于阅读,此条规则优先于下一条。
21.类内方法定义的顺序依次是:公有方法或保护方法 > 私有方法 > getter / setter 方法。
说明:公有方法是类的调用者和维护者最关心的方法,首屏展示最好;保护方法虽然只是子类关心,也可 能是“模板设计模式”下的核心方法;而私有方法外部一般不需要特别关心,是一个黑盒实现;因为承载 的信息价值较低,所有 Service 和 DAO 的
getter/setter方法放在类体最后
- 22.
setter方法中,参数名称与类成员变量名称一致,this.成员名 = 参数名。在getter/setter方法中,不要增加业务逻辑,增加排查问题的难度。
反例:

- 23.循环体内,字符串的连接方式,使用
StringBuilder的append方法进行扩展。
说明:下例中,反编译出的字节码文件显示每次循环都会 new 出一个
StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象,造成内存资源浪费。
反例:

# 日期时间
- 1.日期格式化时,传入
pattern中表示年份统一使用小写的y。
说明:日期格式化时,
yyyy表示当天所在的年,而大写的YYYY代表是week in which year(JDK7 之后 引入的概念),意思是当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,返回的YYYY就是下一年。
正例:

- 2.在日期格式中分清楚大写的
M和小写的m,大写的H和小写的h分别指代的意义。
说明:日期格式中的这两对字母表意如下:
1)表示月份是大写的M
2)表示分钟则是小写的m
3)24 小时制的是大写的H
4)12 小时制的则是小写的h
- 3.获取当前毫秒数:
System.currentTimeMillis(); 而不是new Date().getTime()。
说明:如果想获取更加精确的纳秒级时间值,使用 System.nanoTime 的方式。在 JDK8 中,针对统计时间 等场景,推荐使用 Instant 类。
- 4.不允许在程序任何地方中使用:1)
java.sql.Date。 2)java.sql.Time。 3)java.sql.Timestamp。
说明:第 1 个不记录时间,getHours()抛出异常;第 2 个不记录日期,getYear()抛出异常;第 3 个在构造 方法 super((time/1000)*1000),在 Timestamp 属性 fastTime 和 nanos 分别存储秒和纳秒信息。
反例: java.util.Date.after(Date)进行时间比较时,当入参是 java.sql.Timestamp 时,会触发 JDK BUG(JDK9 已修复),可能导致比较时的意外结果。
- 5.不要在程序中写死一年为 365 天,避免在公历闰年时出现日期转换错误或程序逻辑 错误。
正例:
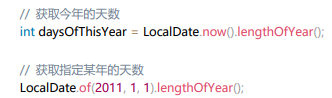
反例:

# 集合处理
1.关于
hashCode和equals的处理,遵循如下规则:- 1)只要覆写
equals,就必须覆写hashCode。 - 2)因为
Set存储的是不重复的对象,依据hashCode和equals进行判断,所以Set存储的对象必须覆写 这两种方法。 - 3)如果自定义对象作为 Map 的键,那么必须覆写
hashCode和equals。
- 1)只要覆写
说明:
String因为覆写了hashCode和equals方法,所以可以愉快地将String对象作为key来使用。
- 2.判断所有集合内部的元素是否为空,使用
isEmpty()方法,而不是size()==0的方式。
说明:在某些集合中,前者的时间复杂度为
O(1),而且可读性更好。
正例:
- 3.在使用
java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要使 用含有参数类型为BinaryOperator,参数名为mergeFunction的方法,否则当出现相同key值时会抛出IllegalStateException异常。
说明:参数
mergeFunction的作用是当出现key重复时,自定义对value的处理策略。
正例:
反例:
- 4.在使用
java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要注 意当value为null时会抛 NPE 异常。
说明:在
java.util.HashMap的merge方法里会进行如下的判断:
反例:
- 5.
ArrayList的subList结果不可强转成ArrayList,否则会抛出ClassCastException异 常:java.util.RandomAccessSubList cannot be cast to java.util.ArrayList。
说明:
subList()返回的是ArrayList的内部类SubList,并不是ArrayList本身,而是ArrayList的一个视 图,对于SubList的所有操作最终会反映到原列表上。
6.使用
Map的方法keySet()/values()/entrySet()返回集合对象时,不可以对其进行添 加元素操作,否则会抛出UnsupportedOperationException异常。7.
Collections类返回的对象,如:emptyList()/singletonList()等都是immutable list, 不可对其进行添加或者删除元素的操作。
反例:如果查询无结果,返回 Collections.emptyList()空集合对象,调用方一旦进行了添加元素的操作,就 会触发 UnsupportedOperationException 异常。
8.在
subList场景中,高度注意对父集合元素的增加或删除,均会导致子列表的遍历、 增加、删除产生ConcurrentModificationException异常。9.使用集合转数组的方法,必须使用集合的
toArray(T[] array),传入的是类型完全一 致、长度为 0 的空数组。
反例:直接使用 toArray 无参方法存在问题,此方法返回值只能是 Object[]类,若强转其它类型数组将出现 ClassCastException 错
正例:
说明:使用 toArray 带参方法,数组空间大小的 length:
1)等于 0,动态创建与 size 相同的数组,性能最好。
2)大于 0 但小于 size,重新创建大小等于 size 的数组,增加 GC 负担。
3)等于 size,在高并发情况下,数组创建完成之后,size 正在变大的情况下,负面影响与 2 相同。
4)大于 size,空间浪费,且在 size 处插入 null 值,存在 NPE 隐患。
- 10.在使用
Collection接口任何实现类的addAll()方法时,都要对输入的集合参数进行 NPE 判断。
说明:在
ArrayList#addAll方法的第一行代码即Object[] a = c.toArray(); 其中 c 为输入集合参数,如果 为null,则直接抛出异常。
- 11.使用工具类
Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法, 它的add/remove/clear方法会抛出UnsupportedOperationException异常。
说明:
asList的返回对象是一个Arrays内部类,并没有实现集合的修改方法。Arrays.asList体现的是适配 器模式,只是转换接口,后台的数据仍是数组。
第一种情况:list.add("yangguanbao"); 运行时异常
第二种情况:str[0] = "change"; 也会随之修改,反之亦然
- 12.泛型通配符来接收返回的数据,此写法的泛型集合不能使用
add方法, 而不能使用get方法,两者在接口调用赋值的场景中容易出错。
说明:扩展说一下 PECS(Producer Extends Consumer Super)原则:第一、频繁往外读取内容的,适合用 。第二、经常往里插入的,适合用
- 13.在无泛型限制定义的集合赋值给泛型限制的集合时,在使用集合元素时,需要进行
instanceof判断,避免抛出ClassCastException异常。
说明:毕竟泛型是在 JDK5 后才出现,考虑到向前兼容,编译器是允许非泛型集合与泛型集合互相赋值。
反例:
- 14.不要在
foreach循环里进行元素的 remove/add 操作。remove 元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。
正例:
反例:
说明:以上代码的执行结果肯定会出乎大家的意料,那么试一下把“1”换成“2”,会是同样的结果吗?
- 15.集合初始化时,指定集合初始值大小。
说明:
HashMap使用HashMap(int initialCapacity)初始化,如果暂时无法确定集合大小,那么指定默 认值(16)即可
正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loader factor)默认 为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。
反例: HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素增加而被迫不断扩容, resize()方法总共会调用 8 次,反复重建哈希表和数据迁移。当放置的集合元素个数达千万级时会影响程序 性能。
*16.使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
说明:
keySet其实是遍历了 2 次,一次是转为Iterator对象,另一次是从 hashMap 中取出 key 所对应的 value。而entrySet只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用Map.forEach方法。
正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是一个 Set 集合对 象;entrySet()返回的是 K-V 值组合集合。
- 17.高度注意
Map类集合 K/V 能不能存储null值的情况,如下表格:
反例:由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储 null 值时会抛出 NPE 异常。
# 并发处理
- 1.获取单例对象需要保证线程安全,其中的方法也要保证线程安全。
说明:资源驱动类、工具类、单例工厂类都需要注意。
- 2.创建线程或线程池时请指定有意义的线程名称,方便出错时回溯。
正例:自定义线程工厂,并且根据外部特征进行分组,比如,来自同一机房的调用,把机房编号赋值给 whatFeatureOfGroup

- 3.线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。 如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
- 4.线程池不允许使用
Executors去创建,而是通过ThreadPoolExecutor的方式,这 样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:
Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和SingleThreadPool:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool:
允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM
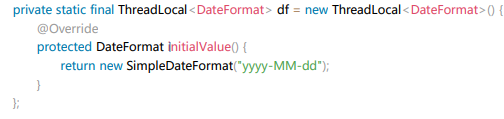
- 5.
SimpleDateFormat是线程不安全的类,一般不要定义为static变量,如果定义为static, 必须加锁,或者使用DateUtils工具类。
正例:注意线程安全,使用 DateUtils。亦推荐如下处理:
- 6.必须回收自定义的
ThreadLocal变量,尤其在线程池场景下,线程经常会被复用, 如果不清理自定义的ThreadLocal变量,可能会影响后续业务逻辑和造成内存泄露等问题。 尽量在代理中使用try-finally块进行回收。
正例:

- 7.高并发时,同步调用应该去考量锁的性能损耗。能用无锁数据结构,就不要用锁;能 锁区块,就不要锁整个方法体;能用对象锁,就不要用类锁。
说明:尽可能使加锁的代码块工作量尽可能的小,避免在锁代码块中调用 RPC 方法。
- 8.对多个资源、数据库表、对象同时加锁时,需要保持一致的加锁顺序,否则可能会造 成死锁。
说明:线程一需要对表 A、B、C 依次全部加锁后才可以进行更新操作,那么线程二的加锁顺序也必须是 A、 B、C,否则可能出现死锁。
- 9.在使用阻塞等待获取锁的方式中,必须在
try代码块之外,并且在加锁方法与 try 代 码块之间没有任何可能抛出异常的方法调用,避免加锁成功后,在finally中无法解锁。
说明一:如果在
lock方法与try代码块之间的方法调用抛出异常,那么无法解锁,造成其它线程无法成功 获取锁。
说明二:如果
lock方法在try代码块之内,可能由于其它方法抛出异常,导致在finally代码块中,unlock对未加锁的对象解锁,它会调用 AQS 的tryRelease方法(取决于具体实现类),抛出IllegalMonitorStateException异常。
说明三:在
Lock对象的lock方法实现中可能抛出unchecked异常,产生的后果与说明二相同。
正例:

反例:


- 10.在使用尝试机制来获取锁的方式中,进入业务代码块之前,必须先判断当前线程是否 持有锁。锁的释放规则与锁的阻塞等待方式相同。
说明:
Lock对象的unlock方法在执行时,它会调用 AQS 的tryRelease方法(取决于具体实现类),如果 当前线程不持有锁,则抛出IllegalMonitorStateException异常。
正例:

- 11.并发修改同一记录时,避免更新丢失,需要加锁。要么在应用层加锁,要么在缓存加 锁,要么在数据库层使用乐观锁,使用 version 作为更新依据。
说明:如果每次访问冲突概率小于 20%,推荐使用乐观锁,否则使用悲观锁。乐观锁的重试次数不得小于 3 次。
12.多线程并行处理定时任务时,
Timer运行多个TimeTask时,只要其中之一没有捕获抛 出的异常,其它任务便会自动终止运行,使用ScheduledExecutorService则没有这个问题。13.
HashMap在容量不够进行resize时由于高并发可能出现死链,导致 CPU 飙升,在 开发过程中注意规避此风险。
# 控制语句
- 1.在一个
switch块内,每个case要么通过continue/break/return等来终止,要么 注释说明程序将继续执行到哪一个case为止;在一个switch块内,都必须包含一个default语句并且放在最后,即使它什么代码也没有。
说明:注意
break是退出switch语句块,而return是退出方法体。
2.当 switch 括号内的变量类型为 String 并且此变量为外部参数时,必须先进行 null 判断。
反例:如下的代码输出是什么?

3.在 if/else/for/while/do 语句中必须使用大括号。
说明:即使只有一行代码,也禁止不采用大括号的编码方式:if (condition) statements;
4.三目运算符 condition? 表达式 1 : 表达式 2 中,高度注意表达式 1 和 2 在类型对齐 时,可能抛出因自动拆箱导致的 NPE 异常。
说明:以下两种场景会触发类型对齐的拆箱操作: 1)表达式 1 或表达式 2 的值只要有一个是原始类型。 2)表达式 1 或表达式 2 的值的类型不一致,会强制拆箱升级成表示范围更大的那个类型
反例:

5.在高并发场景中,避免使用”等于”判断作为中断或退出的条件。
说明:如果并发控制没有处理好,容易产生等值判断被“击穿”的情况,使用大于或小于的区间判断条件 来代替。
反例:判断剩余奖品数量等于 0 时,终止发放奖品,但因为并发处理错误导致奖品数量瞬间变成了负数, 这样的话,活动无法终止
6.当某个方法的代码总行数超过 10 行时,return / throw 等中断逻辑的右大括号后均 需要加一个空行。
7.表达异常的分支时,少用 if-else 方式,这种方式可以改写成:

说明:如果非使用 if()...else if()...else...方式表达逻辑,避免后续代码维护困难,请勿超过 3 层。
正例:超过 3 层的 if-else 的逻辑判断代码可以使用卫语句、策略模式、状态模式等来实现,其中卫语句示例如下:

8.除常用方法(如 getXxx/isXxx)等外,不要在条件判断中执行其它复杂的语句,将复 杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性。
说明:很多 if 语句内的逻辑表达式相当复杂,与、或、取反混合运算,甚至各种方法纵深调用,理解成本 非常高。如果赋值一个非常好理解的布尔变量名字,则是件令人爽心悦目的事情。
正例:

反例:
9.不要在其它表达式(尤其是条件表达式)中,插入赋值语句。
反例:

10.循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、 获取数据库连接,进行不必要的 try-catch 操作(这个 try-catch 是否可以移至循环体外)。
11.避免采用取反逻辑运算符。
说明:取反逻辑不利于快速理解,并且取反逻辑写法一般都存在对应的正向逻辑写法。
正例:使用 if (x < 628) 来表达 x 小于 628。
反例:使用 if (!(x >= 628)) 来表达 x 小于 628。
12.公开接口需要进行入参保护,尤其是批量操作的接口。
反例:某业务系统,提供一个用户批量查询的接口,API 文档上有说最多查多少个,但接口实现上没做任何 保护,导致调用方传了一个 1000 的用户 id 数组过来后,查询信息后,内存爆了。
# 注释规约
- 1.类、类属性、类方法的注释必须使用 Javadoc 规范,使用/*内容/格式,不得使用 // xxx 方式。
说明:在 IDE 编辑窗口中,Javadoc 方式会提示相关注释,生成 Javadoc 可以正确输出相应注释;在 IDE 中,工程调用方法时,不进入方法即可悬浮提示方法、参数、返回值的意义,提高阅读效率。
- 2.所有的抽象方法(包括接口中的方法)必须要用 Javadoc 注释、除了返回值、参数、 异常说明外,还必须指出该方法做什么事情,实现什么功能。
说明:对子类的实现要求,或者调用注意事项,请一并说明。
- 3.所有的类都必须添加创建者和创建日期。
说明:在设置模板时,注意 IDEA 的@author 为
${USER},而 eclipse 的@author 为${user},大小写有 区别,而日期的设置统一为yyyy/MM/dd的格式。
4.方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释使 用/* */注释,注意与代码对齐。
5.所有的枚举类型字段必须要有注释,说明每个数据项的用途。
6.在类中删除未使用的任何字段、方法、内部类;在方法中删除未使用的任何参数声明 与内部变量。
# 前后端规约
- 1.前后端交互的 API,需要明确协议、域名、路径、请求方法、请求内容、状态码、响 应体。
说明:
1)协议:生产环境必须使用 HTTPS。
2)路径:每一个 API 需对应一个路径,表示 API 具体的请求地址:
- a)代表一种资源,只能为名词,推荐使用复数,不能为动词,请求方法已经表达动作意义。
- b)URL 路径不能使用大写,单词如果需要分隔,统一使用下划线。
- c)路径禁止携带表示请求内容类型的后缀,比如
".json",".xml",通过accept头表达即可。
3)请求方法:对具体操作的定义,常见的请求方法如下:
- a)GET:从服务器取出资源。
- b)POST:在服务器新建一个资源。
- c)PUT:在服务器更新资源。
- d)DELETE:从服务器删除资源。
4)请求内容:URL 带的参数必须无敏感信息或符合安全要求;body 里带参数时必须设置 Content-Type。
5)响应体:响应体 body 可放置多种数据类型,由 Content-Type 头来确定。
- 2.前后端数据列表相关的接口返回,如果为空,则返回空数组[]或空集合{}。
说明:此条约定有利于数据层面上的协作更加高效,减少前端很多琐碎的 null 判断。
- 3.服务端发生错误时,返回给前端的响应信息必须包含 HTTP 状态码,errorCode、 errorMessage、用户提示信息四个部分。
说明:四个部分的涉众对象分别是浏览器、前端开发、错误排查人员、用户。其中输出给用户的提示信息 要求:简短清晰、提示友好,引导用户进行下一步操作或解释错误原因,提示信息可以包括错误原因、上 下文环境、推荐操作等。 errorCode:参考附表 3。errorMessage:简要描述后端出错原因,便于错误排 查人员快速定位问题,注意不要包含敏感数据信息。
- 4.在前后端交互的 JSON 格式数据中,所有的 key 必须为小写字母开始的
lowerCamelCase风格,符合英文表达习惯,且表意完整。
正例:errorCode / errorMessage / assetStatus / menuList / orderList / configFlag
反例:ERRORCODE / ERROR_CODE / error_message / error-message / errormessage
5.errorMessage 是前后端错误追踪机制的体现,可以在前端输出到
type="hidden"文字类控件中,或者用户端的日志中,帮助我们快速地定位出问题。6.对于需要使用超大整数的场景,服务端一律使用
String字符串类型返回,禁止使用Long类型。
说明:Java 服务端如果直接返回 Long 整型数据给前端,JS 会自动转换为 Number 类型(注:此类型为双 精度浮点数,表示原理与取值范围等同于 Java 中的 Double)。Long 类型能表示的最大值是 2 的 63 次方 -1,在取值范围之内,超过 2 的 53 次方 (9007199254740992)的数值转化为 JS 的 Number 时,有些数 值会有精度损失。扩展说明,在 Long 取值范围内,任何 2 的指数次整数都是绝对不会存在精度损失的,所 以说精度损失是一个概率问题。若浮点数尾数位与指数位空间不限,则可以精确表示任何整数,但很不幸, 双精度浮点数的尾数位只有 52 位。
反例:通常在订单号或交易号大于等于 16 位,大概率会出现前后端单据不一致的情况,比如,"orderId": 362909601374617692,前端拿到的值却是: 362909601374617660。
7.HTTP 请求通过 URL 传递参数时,不能超过 2048 字节。
8.HTTP 请求通过
body传递内容时,必须控制长度,超出最大长度后,后端解析会出错。
说明:
nginx默认限制是 1MB,tomcat默认限制为 2MB,当确实有业务需要传较大内容时,可以通过调 大服务器端的限制。
9.在翻页场景中,用户输入参数的小于 1,则前端返回第一页参数给后端;后端发现用 户输入的参数大于总页数,直接返回最后一页。
10.前后端的时间格式统一为
"yyyy-MM-dd HH:mm:ss",统一为 GMT。
# 异常日志
# 错误码
- 1.错误码的制定原则:快速溯源、沟通标准化。
说明: 错误码想得过于完美和复杂,就像康熙字典中的生僻字一样,用词似乎精准,但是字典不容易随身 携带并且简单易懂。
正例:错误码回答的问题是谁的错?错在哪?1)错误码必须能够快速知晓错误来源,可快速判断是谁的问 题。2)错误码必须能够进行清晰地比对(代码中容易 equals)。3)错误码有利于团队快速对错误原因达 到一致认知。
- 2.错误码不体现版本号和错误等级信息。
说明:错误码以不断追加的方式进行兼容。错误等级由日志和错误码本身的释义来决定。
3.全部正常,但不得不填充错误码时返回五个零:00000。
4.错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号。
说明:错误产生来源分为 A/B/C,A 表示错误来源于用户,比如参数错误,用户安装版本过低,用户支付 超时等问题;B 表示错误来源于当前系统,往往是业务逻辑出错,或程序健壮性差等问题;C 表示错误来源 于第三方服务,比如 CDN 服务出错,消息投递超时等问题;四位数字编号从 0001 到 9999,大类之间的 步长间距预留 100,参考文末附表 3。
- 5.编号不与公司业务架构,更不与组织架构挂钩,以先到先得的原则在统一平台上进行, 审批生效,编号即被永久固定。
# 异常处理
- 1.Java 类库中定义的可以通过预检查方式规避的
RuntimeException异常不应该通过catch的方式来处理,比如:NullPointerException,IndexOutOfBoundsException等等。
说明:无法通过预检查的异常除外,比如,在解析字符串形式的数字时,可能存在数字格式错误,不得不 通过
catch NumberFormatException来实现。
正例:if (obj != null) {...}
反例:try { obj.method(); } catch (NullPointerException e) {…}
- 2.异常捕获后不要用来做流程控制,条件控制。
说明:异常设计的初衷是解决程序运行中的各种意外情况,且异常的处理效率比条件判断方式要低很多。
- 3.
catch时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。 对于非稳定代码的catch尽可能进行区分异常类型,再做对应的异常处理。
说明:对大段代码进行
try-catch,使程序无法根据不同的异常做出正确的应激反应,也不利于定位问题, 这是一种不负责任的表现。
正例:用户注册的场景中,如果用户输入非法字符,或用户名称已存在,或用户输入密码过于简单,在程 序上作出分门别类的判断,并提示给用户。
4.捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请 将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的 内容。
5.事务场景中,抛出异常被
catch后,如果需要回滚,一定要注意手动回滚事务。6.
finally块必须对资源对象、流对象进行关闭,有异常也要做try-catch。7.不要在
finally块中使用return。
说明:
try块中的return语句执行成功后,并不马上返回,而是继续执行finally块中的语句,如果此处存 在return语句,则在此直接返回,无情丢弃掉try块中的返回点。
反例:

- 8.在调用 RPC、二方包、或动态生成类的相关方法时,捕捉异常必须使用
Throwable类来进行拦截。
说明:通过反射机制来调用方法,如果找不到方法,抛出
NoSuchMethodException。什么情况会抛出NoSuchMethodError呢?二方包在类冲突时,仲裁机制可能导致引入非预期的版本使类的方法签名不匹配, 或者在字节码修改框架(比如:ASM)动态创建或修改类时,修改了相应的方法签名。这些情况,即使代 码编译期是正确的,但在代码运行期时,会抛出NoSuchMethodError。
- 9.方法的返回值可以为
null,不强制返回空集合,或者空对象等,必须添加注释充分说 明什么情况下会返回null值。
# 日志规约
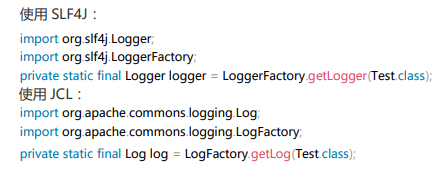
- 1.应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架 (SLF4J、JCL--Jakarta Commons Logging)中的 API,使用门面模式的日志框架,有利于维护和 各个类的日志处理方式统一。
说明:日志框架(SLF4J、JCL--Jakarta Commons Logging)的使用方式(推荐使用 SLF4J)
- 2.所有日志文件至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。对于 当天日志,以“应用名.log”来保存,保存在/home/admin/应用名/logs/目录下,过往日志 格式为: {logname}.log.{保存日期},日期格式:yyyy-MM-dd。
正例:以 aap 应用为例,日志保存在/home/admin/aapserver/logs/aap.log,历史日志名称为 aap.log.2016-08-01
3.根据国家法律,网络运行状态、网络安全事件、个人敏感信息操作等相关记录,留存 的日志不少于六个月,并且进行网络多机备份。
4.应用中的扩展日志(如打点、临时监控、访问日志等)命名方式:
appName_logType_logName.log。logType:日志类型,如stats/monitor/access等;logName:日志描 述。这种命名的好处:通过文件名就可知道日志文件属于什么应用,什么类型,什么目的,也有利于归类查 找。
说明:推荐对日志进行分类,如将错误日志和业务日志分开存放,便于开发人员查看,也便于通过日志对系 统进行及时监控。
正例:mppserver 应用中单独监控时区转换异常,如:mppserver_monitor_timeZoneConvert.log
- 5.在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append()方式,有一定的性能损耗。使用占位符仅 是替换动作,可以有效提升性能。
正例:logger.debug("Processing trade with id: {} and symbol: {}", id, symbol);
6.对于 trace/debug/info 级别的日志输出,必须进行日志级别的开关判断。
7.生产环境禁止直接使用 System.out 或 System.err 输出日志或使用 e.printStackTrace()打印异常堆栈。
说明:标准日志输出与标准错误输出文件每次 Jboss 重启时才滚动,如果大量输出送往这两个文件,容易 造成文件大小超过操作系统大小限制。
- 8.异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过 关键字 throws 往上抛出。
正例:logger.error("inputParams:{} and errorMessage:{}", 各类参数或者对象 toString(), e.getMessage(), e);
- 9.日志打印时禁止直接用 JSON 工具将对象转换成 String。
说明:如果对象里某些 get 方法被覆写,存在抛出异常的情况,则可能会因为打印日志而影响正常业务流 程的执行。
正例:打印日志时仅打印出业务相关属性值或者调用其对象的 toString()方法。
# 安全规约
- 1.隶属于用户个人的页面或者功能必须进行权限控制校验。
说明:防止没有做水平权限校验就可随意访问、修改、删除别人的数据,比如查看他人的私信内容。
- 2.用户敏感数据禁止直接展示,必须对展示数据进行脱敏。
说明:中国大陆个人手机号码显示:139****1219,隐藏中间 4 位,防止隐私泄露。
- 3.用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定,防止 SQL 注入, 禁止字符串拼接 SQL 访问数据库。
反例:某系统签名大量被恶意修改,即是因为对于危险字符 # --没有进行转义,导致数据库更新时,where 后边的信息被注释掉,对全库进行更新。
- 4.用户请求传入的任何参数必须做有效性验证。
说明:忽略参数校验可能导致:
1)page size 过大导致内存溢出
2)恶意 order by 导致数据库慢查询
3)缓存击穿
4)SSRF
5)任意重定向
6)SQL 注入,Shell 注入,反序列化注入
7)正则输入源串拒绝服务 ReDoS
Java 代码用正则来验证客户端的输入,有些正则写法验证普通用户输入没有问题,但是如果攻击人员使用 的是特殊构造的字符串来验证,有可能导致死循环的结果。
5.禁止向 HTML 页面输出未经安全过滤或未正确转义的用户数据。
6.表单、AJAX 提交必须执行 CSRF 安全验证。
说明:CSRF(Cross-site request forgery)跨站请求伪造是一类常见编程漏洞。对于存在 CSRF 漏洞的应用/ 网站,攻击者可以事先构造好 URL,只要受害者用户一访问,后台便在用户不知情的情况下对数据库中用 户参数进行相应修改。
7.URL 外部重定向传入的目标地址必须执行白名单过滤。
8.在使用平台资源,譬如短信、邮件、电话、下单、支付,必须实现正确的防重放的机 制,如数量限制、疲劳度控制、验证码校验,避免被滥刷而导致资损。